

































Cookies help us deliver our services. By using our services, you agree to our use of cookies.
Search
Soft Switching Fails at Scale
Wednesday, December 10, 2014
There is a significant camp of software developers who are developing software switching solutions for hypervisors. Which is nice, I guess. The use of software switching in the hypervisor has some good points but, in my view they are heavily outweighed by the bad.
Update 20140715
Although the logic of this post remains sound at the time it was written, today I take view that several factors have changed my view.
1. X86 server network performance is now able to forward more than 40 gigabits using just a single CPU. This makes the pricing of the 802.1BR/FEX standards unworkable in practice.
2. In 2011, most of networking was about conserving resources and minimising usage of scarce system capacity in terms of bandwidth, capacity, TCAM or configuration time. In 2014, it’s clear that it is cheaper and better to buy use server software, new switches and complement functions with SDN platforms. The cost of time and money in addressing the problems in this article is self-evident.
I’ve written several articles in a series on overlay networking that discuss why I can’t see how or why integration between the overlay and underlay matters. Although there are vendors who make the point that some form of integration is needed, I still don’t see the need. If you want to talk about it, please get it touch to tell me why.
One final point – hardware still matters in the long run. But for the next five years at least, hardware performance does not need conservation for most people. Its cheaper to buy more resources aka hardware with software orchestration than to implement features that conserve them like 802.1BR/FEX.
Software Switching
The idea about software switching is that you can develop some software on in the hypervisor platform that performs all the frame forwarding. The folks over at Network Heresy have pumped out a number of self-serving and bombastic articles declaiming the value of software switching and that all inter-VM traffic should be handled in software. It all sounds very reasonable, but they haven’t discussed to overall picture that includes the larger eco-system.
I, currently, have a different view – let me use a diagram to show my concerns. If you look at the VM elements in a single hardware server and corresponding network connections, then it should summarise down to this:
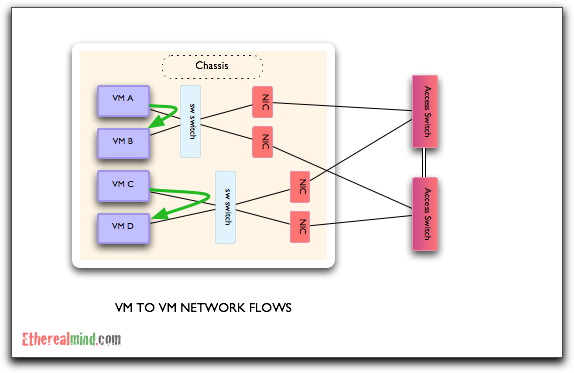
For frames that flow between VM A-B and C-D, the idea of using a software switch makes sense. After all, why send that traffic out from the hypervisor into the network just to switch it back where it came from. It seems rather obvious, but what happens in a much larger network with a number of servers hosting VMs:
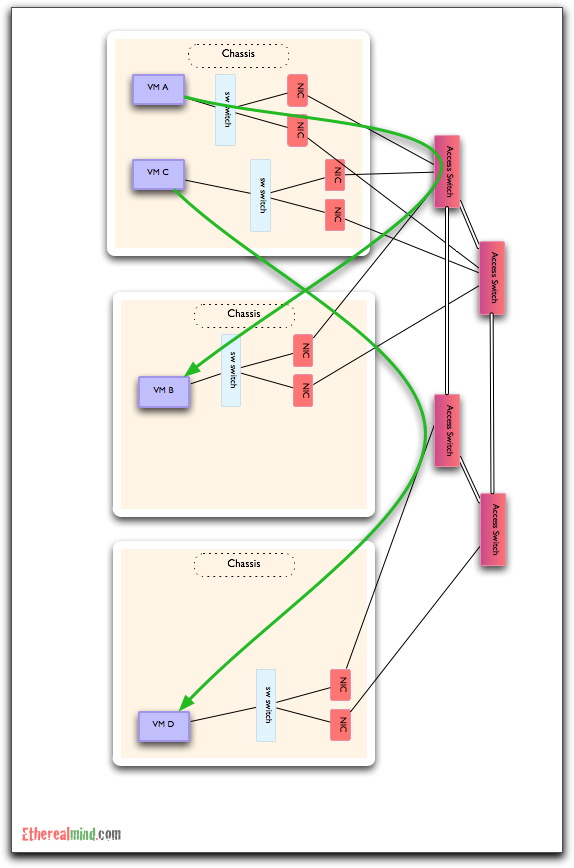
In this diagram, the frame forwarding between VM A-B and C-D will always cross the network. So let’s ask the question.
What is the value of software switching in this scenario ?
The software switching people claim that forwarding 10GbE of Ethernet frames will only one CPU core of a modern Intel server, and that isn’t much of a price to pay for the functionality. Yet, if ALL the frames are forwarded away from the hypervisor, then the software forwarding adds no value.
Ok, that’s not quite true. Using software switching add value where the hypervisor platform can signal between itself the configuration data of the connection to the switch – aka the switch port profile can be fully managed by hypervisor, and moves with the VM as its moves around the hypervisor system.
But, But, But
There is a key point that people often forget. You MUST assume that your VMs are NOT on the same motherboard/hypervisor. You might think that placing Apache and MySQL server on the same hypervisor is good idea for low network latency, and then forget that next week you are highly likely to migrate the MySQL server to new server to provide more RAM and CPU for a performance boost. Or is you are using a dynamic resource scheduler which moves GuestOS around the network on demand, you will never know what the network connection is.
I would strongly make the point that, for most larger sites (where software switching offers the best value), that VMs almost never communicate with each other on the same hypervisor. Therefore, you MIGHT get lower latency within the chassis but you get much higher latency when forwarding off chassis. In modern “blah blah cloud” networks, latency is an absolute that much be reduced so that intersystem communication is as fast possible.
Complexity
The greatest enemy of reliable operation is complexity. I take the view that adding a complex software overlay to a system that already has the necessary features, is going to create serious problems:
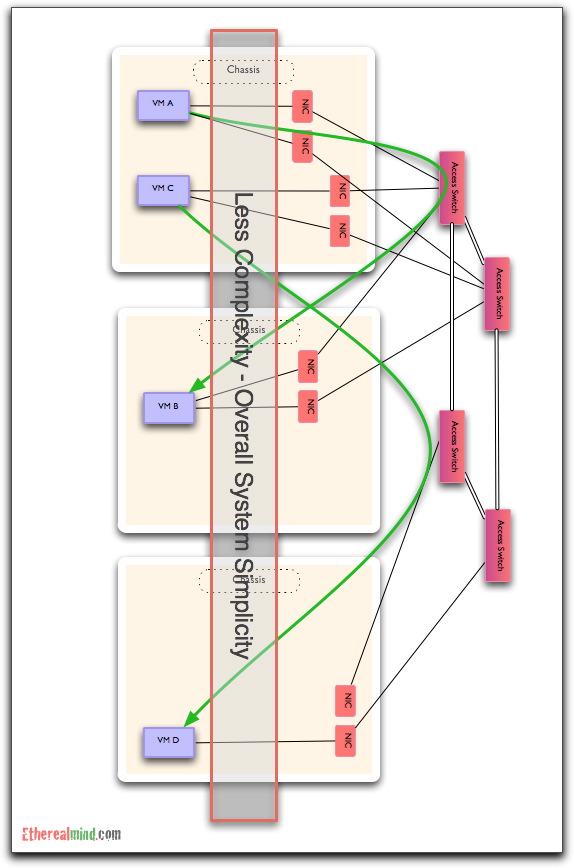
I don’t understand the benefit / impact relationship that would make me accept that adding complexity is viable.
Load and Latency.
In the second article the Network Heresy folks attempts to defend software switching and excoriate SR-IOV in particular.
This quote seems misguided to me:
Another benefit is simple resource efficiency, you already bought the damn server, so if you have excess compute capacity why buy specialized hardware for something you can do on the end host? Or put another way, after you provision some amount of hardware resources to handle the switching work, any of those resources that are left over are always available to do real work running an app instead of being wasted(which is usually a lot since you have to provision for peaks).
This is a schoolboy network design failure – at the very time that peak load is occurring, there is a very high probability that network load is also at peak. Claiming that “unused resources” are used for switching is wrong, and worse, it will catch at the worst possible point in the computing cycle of peak demand — this leads to deadlock design failure.
Of course, there could be some sort of software configuration to overcome this weakness with resource sharing and everyone will forget why it shouldn’t have happened in the first place, and rush out to buy even bigger and more power hungry servers — which suits some of the companies supporting soft switching just fine, thankyou very much e.g. Intel.
Security
Software switching isn’t, and can never be secure. It fails all security profiling checks for multi tenant separation, administrative control and data plane isolation. For monolithic deployments i.e. companies who run just one application (no matter how large) like Facebook, this is fine – but that is a very small part of the market. This means that a significant portion of the market cannot use this technology – and that’s bad for business and bad for the technology overall.
The EtherealMind View
I can see the point of software switching however wittily / pretentiously the argument is made. However, I do not see how it will be successful given the limitations I’ve explained here.
I suspect that Software switching will arrive and fail. After all, a few months with a handful of software developers and VMware or Xen will have a technology that is part of the vCenter management “lock in” and then attempt to convince everyone it is the way forward.
But then people will learn, after a while, that it doesn’t scale. Server Administrators, who make the buying decisions here, aren’t used to thinking in terms of ten or twenty servers at once, so it will take them some time to learn hard lessons about multiple interdependent systems.
Cisco has already released the VM-FEX which, if you agree with my arguments here, is a better overall technology for VM Guest networking. I’m sure the other vendors are also rushing products to market, this is the only one I know about.
My advice ? Don’t be caught out by the short term win of easy and cheap. Consider the bigger picture and understand the implications of your design choices.
Oh wait, I think I’ve said that somewhere before……
Leave your comment